Estimating a new website project may never be entirely predictable, but it is by no means a shot in the dark. We’re constantly refining our process in order to create estimates that are data-driven, transparent, and reliable. Here’s a look at our latest evolution.


Often, clients want to leverage our team’s brand design, copywriting, SEO, and content population services, but we account for these as separate scopes outside of the engineering estimate.
With the task list framework in place, our engineers proceed to review the UI in depth to ensure the thoroughness of our list.

Applying a Formula to Each Task
After creating a thorough list of all a project’s tasks, we then proceed to estimate each one with a formula. This is where the data we’ve collected and the experience we’ve gained form past projects comes into play.
We use two types of formulas on our estimates:
- A three-point formula for engineering tasks
- A simple percentage for relative tasks
Let’s take a look at each of them.
Three-point Formula (for Engineering Tasks)
Engineering tasks use three data points and a weighted average to calculate estimated time to a high degree of accuracy. Why do we use three data points? It makes our estimates more realistic.
Here’s an example of a single data point estimate for a callout module:
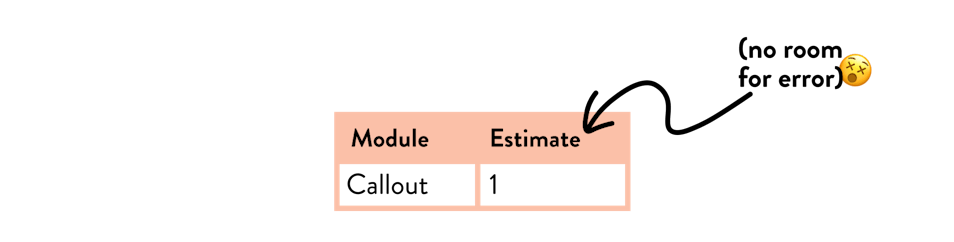
While that is certainly suitable for a small, predictable module, it doesn’t allow much wiggle room if development moves slower or faster than expected.
Two data points (a high and and low end) with an average would be better:
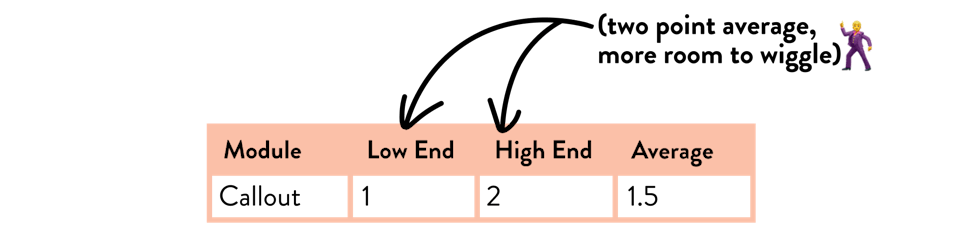
But three data points would be better still. This allows us to take three scenarios into account:
- An Optimistic Estimate - if we’re developing on a bright sunny day, the flowers are blooming, the birds are singing and everything is going faster than we thought it would go
- A Realistic Estimate - exactly what we expected happened
- A Pessimistic Estimate - 17 things when wrong that we could not have known about, and there was a thunderstorm to boot!
In addition, we can give more weight to the realistic data point since in our experience it is the most likely outcome. The resulting formula looks like this.
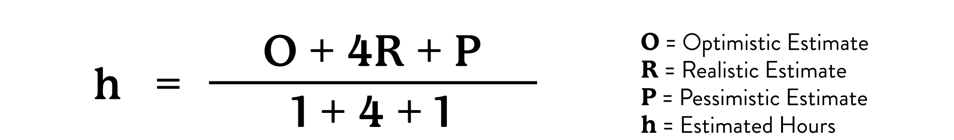

This feels intuitive and has worked well for engineering tasks.
We could take this a step further still by having multiple developers create estimates and comparing their results.
Percentage (for Relative Tasks)
Relative tasks constitute Developer Meetings, QA Revisions, and Account Management and the like. Tasks like these have proven to be related to the total time spent on initial development, so we estimate them using a simple percent. We set the percent for a relative task based on the average we’ve calculated from similar projects. For example:


We also have percentages defined based on the number of developers who will be working on a project simultaneously.
Live Example
Have a look at this example of a minimal estimate spreadsheet to help you visualize what we’re talking about.
To ensure that we put the data we collect into action, we schedule a team review (post mortem) at the end of each project and analyze time spent. We also maintain a master spreadsheet that contains all the engineering projects we’ve completed for the last several years, and use it to both calculate and update our formulas on a regular basis.
So there you have it—by regularly collecting data and developing reliable formulas we’ve been able to estimate projects with a high level of accuracy. Our clients have appreciated our attention to detail and transparency, and our team feels supported with realistic expectations.